웹 페이지 이벤트 적재 파이프라인 생성
웹 페이지 기반 플랫폼 기업은 사용자의 동작으로 발생되는 모든 로그를 안정적으로 수집하기 위해 상당한 노력을 한다.
사용자의 특징을 파악하기 위해 사용자가 수행하는 모든 클릭, 스크롤, 입력과 같은 내용을 수집하고, 수집된 사용자 이벤트들은 적절한 형태로 가공되어 광고, 신용도 측정, 이상 동작 감지등으로 사용된다.
이러한 이벤트 수집은 서비스에 영향을 미치지 않으면서 안정적으로 유지되어야 하는데 수집을 하기 위해서 사용자에게 영향이 있는다면 고객 경험에 좋지 않은 영향을 미치기 때문이다.
카프카에는 예상치 못한 데이터의 급격한 증가가 발생해도 안정적으로 운영하는데 강점이 있다.
이벤트가 많이 발생하더라도 발생한 이벤트들은 모두 카프카의 토픽에 쌓이기 때문에 컨슈머는 자신이 할 수 있는 만큼 최종 적재 애플리케이션에 저장하면 된다.
적재 정책
파이프라인의 운영 난이도는 정책에 따라 달라진다.
만약 일부 데이터가 유실이나 중복 적재되어도 무관하다면 운영 난이도가 낮지만, 데이터가 유실, 중복 없이 한번 적재되는 정책이라면 운영 난이도가 올라간다.
0.11.0.0 이전 버전의 카프카는 적어도 한 번 이상 전달을 만족했지만 이후 멱등성 프로듀서를 통해 정확히 한 번 전달을 지원한다.
이때 전달된다는 것은 적재된다는 것과 다른것으로 전달은 단순히 프로듀서로부터 브로커까지 전달되는 것이고, 적재는 프로듀서로부터 컨슈머를 넘어 최종적으로 하둡이나 엘라스틱서치까지 데이터가 저장되는 것을 의미한다.
따라서 정확히 한 번 전달되더라도 컨슈머의 커밋 시점과 데이터 적재가 동일 트랜잭션에서 처리되지 않으면 정확히 한 번 적재되지 않을 수 있다.
실제로 HDFS 적재, S3 적재 컨슈머 애플리케이션에서는 컨슈머의 커밋과 저장이 동일 트랜잭션으로 처리하는 것이 불가능하기 때문에 컨슈머의 장애가 발생하면 정확히 한 번 적재하지 못한다.
이러한 경우 이슈 발생 시점을 확인하고 특정 파티션의 특정 오프셋부터 다시 적재해야한다.
만약 정확히 한 번 적재가 필요한 경우 멱등성 프로듀서를 사용하고 고유한 키를 지원하는 데이터베이스 시스템에 적재하는것이 좋다.
예를들어 MySQL의 고유키를 가진 테이블을 생성하고 해당 테이블에 insert하는 파이프라인을 만들면 컨슈머가 중복해서 insert하더라도 이미 고유키로 적재된 데이터가 있어 중복 적제되지 않는다.
파이프라인 정책
일부 데이터의 유실 또는 중복 허용
안정적으로 끊임없는 적재
갑작스럽게 발생하는 많은 데이터양을 허용
데이터 포맷
VO(value object)형태로 객체를 선언하여 직렬화 하여 전송하는 방법은 보편적이고 편리하지만 프로듀서와 컨슈머에서 동일한 버전의 VO객체를 선언해서 사용해야 한다는 문제점이 있다.
그리고 스키마가 변경될 경우 프로듀서와 컨슈머 모두 소스코드의 업데이트가 필요하여 비용이 크다.
또한 직렬화된 객체는 kafka-console-consumer 명령어를 통해서 내부 데이터를 볼 수 없기 때문에 디버깅이 어려워 해당 객체에 특화된 역직렬화 클래스가 필요하다.
스키마의 변화에 유연하면서 명령어를 통해 편리하게 데이터를 출력할 수 있는 데이터 포맷으로 JSON이 있다.
이는 키-값 쌍으로 이루어진 구조를 가지고 있어 스키마 변경에 유연하게 대처할 수 있고, string으로 선언되어 string또는 bytearray로 직렬화 되어 전송되어 kafka-console-consumer명령어로 데이터 출력이 가능하다.
프로듀서
웹 페이지에서 생성된 이벤트를 받는 REST API클라이언트를 만들고 전달받은 이벤트를 가공하여 토픽으로 전달한다.
프로듀서를 운영할 때 처음 고민해야 할 옵션은 ack를 어떤 값으로 설정할지이다.
acks를 all로 설정하면 이상이 생겼을 때 복구할 학률이 높지만 그만큼 데이터를 저장하는데 시간이 오래 걸린다.
반면 0또는 1로 설정을 하면 속도는 빠르지만 이상이 생겼을 때 데이터를 복구하지 못하고 유실이 발생할 수 있다.
0으로 설정한 경우 프로듀서가 메시지를 보낼 때 브로커로부터 아무런 응답을 기다리지 않는다.
1로 설정한 경우 메시지를 브로커에 보내고 해당 메시지가 리더 파티션에 기록이 되었는지 확인하는 응답을 기다린다.
이를 통해 리더 파티션에는 데이터가 적재되는것이 보장이 되지만 팔로워 파티션에는 복제되지 않을 수 있어 리더에 문제가 발생하면 메시지를 복구하지 못할 수 있다.
재시도 설정에서 클러스터 또는 네트워크 이슈로 데이터가 정상적으로 전송이 되지 않았을 때 프로듀서는 다시 전송을 시도한다.
이때 토픽으로 전송된 데이터의 중복이 발생할 수 있고, 전송 시점의 역전으로 인해 전송 순서와 토픽에 적재된 데이터의 순서가 바뀔 수 있다.
프로듀서 압축 옵션
프로듀서의 압축은 gzip, snappy, lz4, zstd 중 한 개를 고를 수 있다.
압축을 하면 클러스터에 적재되는 데이터의 총 용량을 줄이고 네트워크의 사용량을 줄이는데 효과적이다.
하지만 프로듀서와 컨슈머에서 데이터를 사용할 때 cpu와 메모리 사용량이 늘어나고 압축을 하지 않았을 때보다 처리량이 줄어들 수 있다.
토픽
토픽을 설정할 때 가장 처음 고민하는 것은 파티션의 수 이다.
파티션 개수는 데이터 처리 순서를 지켜야 하는지 여부에 따라 엄격하게 정할지 말지 결정한다.
하둡 또는 엘라스틱서치에 데이터를 순서대로 적재해야 한다면 파티션 개수를 엄격하게 정해야한다.
그러나 데이터를 순서대로 적재하지 않더라도 이벤트가 발생 할 때 이벤트 발생 시간을 데이터에 같이 조합해 보내면 하둡과 엘라스틱서치에서 데이터를 조회할 때 시간 순서대로 조회 할 수 있다.
이벤트 발생 시간이 데이터에 포함되면 하둡 또는 엘라스틱서치에 적재되는 순서가 이벤트 발생 순서와 달라도 되기 때문에 파티션을 여러개로 생성하여 병렬로 컨슈머를 운영해도 된다.
컨슈머
토픽에 저장되어 있는 웹 이벤트를 하둡과 엘라스틱서치에 저장하는 로직을 만드는 방법은 두 가지가 있다.
1. 컨슈머 API를 사용하여 직접 개발
타깃 애플리케이션과 연동하는 라이브러리를 직접 선택하여 적용할 수 있다.
또한 컨슈머 내부 로직에 타깃 애플리케이션과 연동시 최적화 할 수 있는 옵션을 제한 없이 적용할 수 있어 개발 허용 범위가 넓다.
2. 분산 커넥트 사용
REST API를 통해 커넥터로 반복적인 파이프라인을 생성할 수 있고, 직접 커넥터를 개발하여 커넥트에 적용하여 사용할 수 있다.
상용 인프라 아키텍처
상용환경의 웹 이벤트 수집 파이프라인을 구축하기 위해서 요구사항과 리소스를 고려해야한다.

• L4 로드밸런서 : 웹 이벤트를 받아서 프로듀서로 분배 역할
• 프로듀서 : 2개 이상의 서버, 각 서버당 1 개 프로듀서
• 카프카 클러스터 : 3개 이상의 브로커로 구성
• 컨슈머 : 2 개 이상의 서버, 각 서버당 1 개 컨슈머
• 커넥트 : 2 개 이상의서버, 분산모드커넥트로구성
안정적인 데이터 파이프라인을 운영하기 위해서 서버의 장애에도 영향을 받지 않도록 이중화 설계를 해야한다.
서버 지표 수집 파이프라인 생성과 카프카 스트림즈 활용
서버를 관리하기 위해 중요 모니터링 정보로 서버의 cpu, 메모리, 네트워크, 디스크 지표를 수집해야한다.

카프카는 불특정 다수 서버의 지표를 수집하는데 용이한데, 서비스 하고 있는 서버들의 수가 상황에 따라 늘어나고 줄어드는데 카프카는 스케일 아웃 또는 파티션의 수를 늘림으로 유연하게 대응하여 스트리밍 데이터 처리를 할 수 있다.
컴퓨터 서버 지표 중 CPU와 메모리 데이터를 수집하여 토픽으로 전송을 한다.
이때 로컬 컴퓨터의 CPU사용량이 50%가 넘을 경우 hostname과 timestamp정보를 비정상 CPU토픽으로 전송한다.
서버 지표 수집에는 메트릭비트를 확용하는데 이는 서버 지표 수집에 특화된 경량 에이전트로 CPU, 메모리, 네트워크 등 서버 모니터링에 필요한 거의 모든 지표를 수집할 수 있고, 수집된 데이터는 카프카 모듈을 통해서 카프카로 전송이 된다.
정책 및 기능 정의
적재 정책
서버들의 지표를 모으는 이유는 사용자가 서버 상태를 모니터링 할 수 있도록 도와주기 위함이다.
따라서 만약 클러스터의 브로커 중 일부에 장애가 발생하여 장애를 복구하는 동안 서버의 상태를 모니터링하지 못하는 것이 매우 치명적이기 때문에 데이터를 적재할 때 지속적으로 데이터를 처리할 수 있으면서 일부 데이터가 유실되거나 중복되는 것을 감안해 파이프라인을 구성하는 것이 중요하다.
토픽
필요한 토픽은 전체 서버의 지표를 저장하는 토픽, CPU 지표만 저장하는 토픽, 메모리 지표만 저장하는 토픽, 비정상 CPU지표를 저장하는 토픽으로 4개이다.
각 서버 지표를 처리하는데 엄격한 처리순서보다는 유연하고 처리량을 늘리는게 중요하여 별도의 메시지 키는 사용하지 않는다.
카프카 스트림즈
수집된 서버의 지표 데이터를 분기처리하고 필터링하는 동작은 카프카 스트림즈가 최적이다.
카프카 스트림즈로 개발할 때는 요구사항에 맞는 형태로 토폴로지를 그리고 각 프로세서에 맞는 DSL메서드를 찾아 적용하면 된다.
이때 스트림즈 DSL메서드로 처리가 불가능하다면 프로세서 API를 사용하면 된다.
미러메이커2를 사용한 토픽 미러링
카프카를 사용할 때 서비스 단위로 클러스터를 구축하여 사용하는 경우가 많다.
따라서 카프카에 이미 저장된 토픽의 데이터를 보내서 2개의 클러스터를 미러링하여 사용한다.
만약 클러스터A에 a라는 토픽이 있으면 이를 클러스터B에서 사용하기 위해서 해당 토픽을 복사해야한다.
이때 토픽 데이터를 실시간으로 미러링하는데 미러메이커2가 유용하게 쓰인다.
이는 데이터를 옮길뿐만 아니라 토픽의 파티션 개수, 새로운 토픽, 토픽 설정 변화를 감지하는 기능까지 가지고 있다.
미러메이커2 운영시 고려할 점
각 클러스터의 보안: 클러스터에 보안 설정이 되어있으면 권한을 획득하고 접근이 가능하게 해야한다.
미러링 토픽 이름: 정규식으로 토픽을 표현하여 미러메이커2를 재시작할 필요 없이 토픽이 생성되는 대로 모두 미러링 할 수 있다.

기능 구현
아키텍처 구현을 위해 미러메이커2 설정을 진행한다.
config 폴더에 connect-mirror-maker.properties파일을 아래와 같이 변경
vi config/connect-mirror-maker.properties
clusters = A, B
A.bootstrap.servers = my-kafka:9092
A.bootstrap.servers = localhost:9092
A->B.enabled = true
A->B.topics = weather.seoul
B->A.enabled = false
B->A.topics = .*
replication.factor = 1
checkpoints.topic.replication.factor=1
hearbears.topic.replication.factor=1
offset-syncs.topic.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
config.storage.replication.factor=1
기능 테스트
weather.seoul토픽 생성
bin/kafka-topics.sh --creare \
--bootstrap-server my-kafka:9092 \
--partitions 3 \
--topic weather.seoul
미러메이커2 실행
bin/connect-mirror-maker.sh config/connect-mirror-maker.properties토픽이 생성되었는지 확인
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
미러링된 토픽의 파티션 수 확인
bin/kafka kafka-topics.sh --bootstrap-server localhost:9092 --topic A.weather.seoul --describe
클러스터A에 보낸 데이터가 클러스터B에 복제 되는지 확인
bin/kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic weather.seoul
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic weather.seoul --from-beginning
상용 인프라 아키텍처
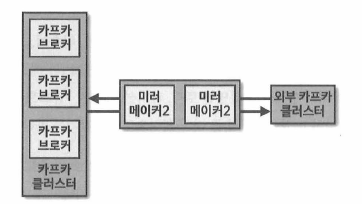
이미지에서는 미러메이커2를 실행하는 서버를 2대 배치하고 카프카 클러스터의 브로커 개수를 3개로 운영하여 일부 서버에 이슈가 발생하더라도 안전하게 토픽을 미러링 할 수 있다.
분산 모드 커넥트를 운영중이라면 별도로 미러메이커2를 위한 서버를 구축하지 않아도 된다.
미러메이커2는 커넥터로도 동작하도록 만들어졌다.
분산 모드 카프카 커넥트를 실행하면 미러링을 위한 커넥터가 준비되어 있으므로 따로 프로세스를 띄울 필요 없이 분산 모드 커넥트에서 미러메이커2 커넥터를 운영하는 방법도 있다.
'컴퓨터 > 아파치 카프카' 카테고리의 다른 글
| 5. 카프카 상세 개념 (0) | 2024.10.02 |
|---|---|
| 4. 카프카 스트림즈와 카프카 커넥트 (4) | 2024.09.25 |
| 3. 카프카 기본 개념 설명 (2) | 2024.09.17 |
| 1. 아파치 카프카란? (2) | 2024.09.11 |



