카프카의 탄생
링크드인에서 파편화된 데이터 수집 및 분배 아키텍처를 운영하는데 어려움이 있었다.
데이터를 생성하고 적재하기 위해서 데이터를 생성하는 소스 애플리케이션과 데이터가 적재되는 타깃 애플리케이션을 연결해야한다.
초기에는 단방향 통신을 통해 연동하는 소스코드를 작성했지만 아키텍처가 거대하고 연결되는 애플리케이션의 수가 증가하면서 문제가 생겼다.
이렇게 파편화된 데이터 파이프라인의 복잡도를 낮추기 위해서 아파치 카프카를 만들었고 이는 애플리케이션의 데이터를 한 곳에 모아 중앙집중화적으로 처리하였다.
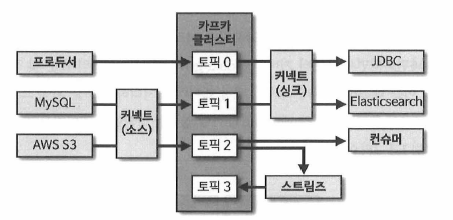
카프카를 중앙에 배치하여 소스와 타깃사이의 의존도를 최소화하여 프로듀서가 애플리케이션에서 생성되는 데이터가 카프카로 넣으면 FIFO방식으로 컨슈머가 데이터를 가져간다.
그리고 카프카는 3대 이상의 서버에서 분산으로 운영하기 때문에 전송받은 데이터를 안전하게 기록하여 일부 서버에 장애가 생겨도 지속적으로 복제를 통해 안전하게 운영할 수 있다.
3대 이상의 서버를 사용하는 이유는 1대로 할 경우 브로커에 장애가 발생할 경우 바로 서비스의 장애로 이어지게 되고, 2대인 경우 1대의 브로커에 장애가 생겨도 안정적으로 데이터 처리를 할 수 있으나, 카프카는 데이터의 고가용성을 보장하기 위해 데이터를 여러 브로커에 복제를 하는 리플리케이션을 하는데 이때 복제를 하기전에 장애가 나면 데이터가 유실될 수 있는 문제가 있다.
따라서 3대 이상의 브로커들로 구성해야 한다.
빅데이터에서 카프카
현대의 IT서비스는 디지털 정보로 기록되는 모든것을 저장하기 때문에 매우 많은 데이터가 있고 여기에는 일정한 규격이 있는 정형데이터부터 음성 영상과 같은 비정형 데이터까지 포함되어 있다.
이를 기존의 DB로 관리는 불가능하기 때문에 이를 저장하고 활용하기 위해서 일단 생성되는 데이터를 모두 모으는 데이터 레이크라는 개념이 사용된다.
데이터 레이크는 데이터 웨어하우스와 다르게 필터링되거나 패키지화 되지 않는 데이터가 저장이 된다. 그리고 사람들은 이 데이터를 토대로 인사이트를 찾는다.
서비스에서 발생하는 데이터를 데이터 레이크로 모으기 위해서 데이터를 직접 넣는다면 복잡도가 올라가고 파편화되기 때문에 데이터를 추출해서 적재하는 과정을 묶는 파이프라인을 구축해야한다.
카프카의 장점
높은 처리량
카프카는 묶어서 보내기 때문에 배치로 빠르게 처리가 가능하다.
그리고 파티션 단위를 통해 동일 목적의 데이터를 분배하여 병렬처리하여 처리량을 늘릴 수 있다.
확장성
데이터가 항상 일정하게 들어오는게 아니기 때문에 특정 이벤트로 매우 많은 데이터가 들어오는 경우가 있다.
카프카는 이런 가변적인 환경에 안정적으로 확장 가능하여 데이터가 적을때는 브로커의 수를 최소로 운영하다 데이터가 많으면 스케일 아웃을 통해 자연스럽게 늘려 처리한다.
영속성
데이터를 파일 시스템에 저장하기 때문에 장애 발생으로 인해 급작스럽게 종료되어도 안전하게 데이터를 처리할 수 있다.
고가용성(HA)
3개 이상의 서버들로 운영되는 카프카 클러스터는 장애가 발생해도 다른 브로커에도 저장이 되어있기 때문에 지속적으로 데이터 처리가 가능하다.
데이터 레이크 아키텍처
데이터 레이크의 아키텍처에는 람다 아키텍처와 카파 아키텍처가 있다.
람다 아키텍처
람다 아키텍처는 레거시 데이터 수집 플랫폼을 개선하기 위해 구성한 아키택처이다.
초기 빅데이터 플랫폼은 엔드 투 엔드로 애플리케이션으로부터 데이터를 배치로 모았다.
하지만 이는 데이터의 인사이트를 빠르게 전달하지 못하는 단점이 있었고, 파생된 히스토리를 파악하기 어려워 데이터가 파편화되면서 데이터 표준 정책을 지키기 어려웠다.
이를 해결하기 위해 스피드레이어를 추가하여 실시간 데이터 ETL작업 영역을 만들었다.
ETL은 추출(Extract), 변환(Transform), 로드(Load)를 나타내며 조직에서 여러 시스템의 데이터를 단일 데이터베이스, 데이터 스토어, 데이터 웨어하우스 또는 데이터 레이크에 결합하기 위해 일반적으로 허용되는 방법이다.

람다 아키텍처는 3가지 레이어로 나뉘는데 먼저 배치 레이어는 배치 데이터를 모아서 특정 시간, 타이밍 마다 일괄 처리한다.
서빙 레이어는 가공된 데이터를 데이터 사용자 서비스 애플리케이션이 사용할 수 있도록 저장을 한다.
스피드 레이어는 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도로 사용한다.
카프카는 스피드 레이어에 위치하여 실시간 데이터를 짧은 지연시간으로 처리하고 분석한다.
카파 아키텍처
데이터를 배치처리하는 레이어와 실시간 처리하는 레이어를 분리한 람다 아키텍처는 데이터 처리 방식을 명확히 나눌 수 있지만 레이어가 2개이기 때문에 데이터 분석과 처리하는데 필요한 로직이 따로따로 존재해야한다는 점과, 두 데이터를 융합할 때 유연하지 못한 파이프라인을 생성해야한다는 단점이 있다.
이러한 단점을 해소하기 위해 카파 아키텍처를 제안했는데 이는 배치 레이어를 제거하고 모든 데이터를 스피드 레이어에 넣어서 처리를 한다.

하지만 이는 모든 데이터를 스피드 레이어에서 처리해야하기 때문에 생성되는 모든 종류의 데이터를 스트림 처리해야한다.
배치 데이터는 한정된 기간 단위 데이터를 일괄 처리하는 특징이 있다.
스트림 데이터는 끝과 끝이 명확히 정해지지 않은 데이터로 보통 작은 단위로 쪼개져 있는 데이터를 뜻한다.
로그를 통해서 각 데이터에 일정한 번호를 붙여 배치 데이터를 로그로 표현할 때 배치 데이터의 변환 기록만 기록하여 모든 데이터를 저장하지 않고 배치 데이터를 표현할 수 있게 되었다
이를 위해서 변환 기록이 일정기간동안 삭제되지 않고 지속적으로 추가되어야 한다.
만약 변화량이 많다면?
변화량이 많은 경우 로그만 기록하는 경우가 더 큰 오버헤드를 발생시킬 수 있다.
https://docs.confluent.io/kafka/design/log_compaction.html
Kafka Log Compaction | Confluent Documentation
The following image provides the logical structure of a Kafka log, at a high level, with the offset for each message. The head of the log is identical to a traditional Kafka log. It has dense, sequential offsets and retains all messages. Log compaction add
docs.confluent.io
같은 내용에 대해서는 최신 상태만 유지하여 로그의 크기를 관리할 수 있다.
그리고 변화량이 매우 빈번하여 모든 데이터를 저장해야할때는 주기적인 스냅샷을 통해 전체 상태를 저장하는 방법을 사용할 수 있다.
그리고 모든 데이터가 스피드 레이어에 들어오기때문에 스피드레이어를 구성하는 데이터 플랫폼은 SPOF가 될 수 있다.
SPOF는 Single Point of Failure라는 뜻으로 시스템에서 하나의 구성 요소나 노드가 실패할 경우, 전체 시스템이 중단되거나 비정상적으로 작동하게 되는 지점을 의미한다.
따라서 내결함성과 장애허용 특징을 지녀서 시스템이 일부 구성 요소가 고장나더라도 시스템 전체가 영향을 받지 않고 정상적으로 작동하고, 고장이 발생함을 허용해 고장이 시스템 전체에 심각한 영향이 안되도록 설계를 해야한다.
데이터 레이크 아키텍처
이후 카파 아키텍처에서 서빙레이어를 제거한 스트리밍 데이터 레이크 아키텍처를 제안했다.

서빙 레이어는 하둡과 같이 데이터 플랫폼에서 사용되는 저장소인데 굳이 카프카를 통해 분석하고 프로세싱한 데이터를 다시 서빙레이어의 저장소에 저장할 필요가 없다고 생각했다.
이러한 과정을 통해 이중으로 관리되는 운영 리소스 최소화하였다.
이제 스피드 레이어에서 데이터 분석, 프로세싱 저장까지 하여 단일 진실 공급원 SSOT가 되었다.
개선사항
자주 접근하지 않는 데이터를 오브젝트 스토리지와 같이 저렴하면서 안전한 저장소에 옮겨서 저장하고 자주 사용하는 데이터만 브로커에서 사용하는 구분 작업이 필요하다.
이에 대한 사항은 kip-405티켓에 있고 현재 Accepted되었다. (티켓은 소프트웨어 개발 프로젝트에서 사용되는 용어로, 문제점, 요청, 개선 사항, 버그 리포트 등을 추적하기 위해 발행된 항목)
https://cwiki.apache.org/confluence/display/KAFKA/KIP-405%3A+Kafka+Tiered+Storage
KIP-405: Kafka Tiered Storage - Apache Kafka - Apache Software Foundation
Authors Satish Duggana, Sriharsha Chintalapani, Ying Zheng, Suresh Srinivas Status Current State: "Accepted" Discussion Thread: here JIRA: KAFKA-7739 - 이슈 세부사항 가져오는 중... 상태 Motivation Kafka is an important part of data infrastr
cwiki.apache.org
참고자료
https://cloud.google.com/learn/what-is-etl?hl=ko
https://cloud.google.com/learn/what-is-etl?hl=ko
cloud.google.com
'컴퓨터 > 아파치 카프카' 카테고리의 다른 글
| 6. 카프카 실전 프로젝트 (1) | 2024.11.07 |
|---|---|
| 5. 카프카 상세 개념 (0) | 2024.10.02 |
| 4. 카프카 스트림즈와 카프카 커넥트 (4) | 2024.09.25 |
| 3. 카프카 기본 개념 설명 (2) | 2024.09.17 |



