쿠버네티스 구성
쿠버네티스는 마스터 노드와 워커 노드라는 두 가지 종류의 노드로 구성되어있다.
여기서 마스터 노드는 클라이언트의 API요청을 받고 워커 노드를 다루는 역할을 하고, 워커 노드는 실제 컨테이너를 실행하는 역할을 한다.
쿠버네티스의 구성을 알아보기 위해서 먼저 클러스터 정보와 노드 정보는 다음과 같이 확인 할 수 있다.


위를 보면 myserver01, 02, 03모두 클러스터로 구성되어 있는것을 볼 수 있다.

파드 목록을 보면 이전에 실행했던 hello world파드가 있음을 볼 수 있다.
여기서 -o wide옵션을 사용하면 더 자세한 정보를 확인할 수 있다.
이제 이전에 있는 파드를 실행해 볼 것인데 아래와 같이 run을 통해서 실행시킬 수 있다.
실행중인 파드 정보를 보면 이름, 상태, 재시작 횟수에 대해서 알 수 있다.

매니페스트를 통한 파드 실행
매니페스트는 쿠버네티스 오브젝트를 생성하기 위한 메타 정보를 YAML이나 JSON형식으로 작성한 파일을 의미한다.
# 매니페스트 파일 생성
apiVersion: v1
kind: Pod # 생성할 오브젝트 종류
metadata:
name: nginx01 # 생성할 오브젝트 메타 정보
spec:
containers:
- name: nginx-test01 # 컨테이너 이름
image: nginx:latest # 생성시킬 이미지
이와 같이 YAML파일을 생성하면 apply를 통해 파드를 생성할 수 있다.

이처럼 kubectl [실행할 동작] -f [파일명]을 통해서 파드의 동작을 할 수 있다.
디플로이먼트
레플리카셋은 특정한 수의 파드가 항상 실행 중이도록 보장하는 역할을 한다.
예를 들어, 3개의 파드가 항상 실행 중이어야 한다고 설정하면, 레플리카셋은 파드가 하나 죽거나 없어졌을 때 자동으로 새로운 파드를 생성하여 다시 3개를 유지하도록 해준다.
쿠버네티스에서 파드를 관리하기 위해서 디플로이먼트라는 개념을 사용하는데, 여기서 디플로이먼트는 레플리카셋을 직접 다루는 대신, 디플로이먼트를 통해 레플리카셋을 관리한다.
즉, 디플로이먼트는 레플리카셋을 생성하고 관리하는 상위 개념이다.
디플로이먼트를 이용하면 새로운 애플리케이션 버전을 배포하거나, 버그가 발생했을 때 이전 버전으로 쉽게 롤백할 수 있는 장점이 있다.

디플로이먼트는 아래와 같이 create deployment를 통해서 생성할 수 있다.
생성을 한 뒤에는 kubectl get 명령어를 통해 pod, replicaset, deployment정보를 각각 확인할 수 있다.
이때 deployment는 줄여서 deploy로, replicaset은 줄여서rs, pod는 줄여서po라고 사용해도 된다.

레플리카셋은 원하는 파드 개수만큼 유지시키기 때문에 디플로이먼트를 통해 레플리카셋의 파드 수를 아래와 같이 조정을 할 수 있다.

위의 실행 결과를 보면 각각의 pod가 어디서 실행되는지 알 수 있는데 2개의 pod는 myserver03에서 실행중이고, 1개의 pod는 myserver02에서 실행중인 것을 볼 수 있다.
이들은 각각의 노드에 흩어져 있지만 하나의 레플리카셋, 하나의 디플로이먼트에 속한것이다.
그리고 디플로이먼트를 생성할 때 레플리카셋을 3으로 설정했기 때문에 delete를 통해서 삭제를 하더라도 다시 pod의 수를 유지하기 위해서 pod가 다시 생성된 것을 볼 수 있다.
# 디플로이먼트 실행위한 매니페스트 파일
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-test01 # 생성할 디플로이먼트 이름
spec:
replicas: 3 # 생성할 레플리카셋의 수
selector:
matchLabels:
app.kubernetes.io/name: web-deploy
template: # 생성할 파드의 정보 표현
metadata:
labels:
app.kubernetes.io/name: web-deploy # 디플로이먼트가 관리할 파드 라벨
spec:
containers:
- name: nginx
image: nginx:latest
위의 코드를 보면 web-deploy라는 이름으로 디플로이먼트와 파드가 묶인다.
이 이름은 selector로 적용하는 이름이 되기 때문에 파드를 생성했을 때의 이름과 동일하다.

위를 보면 디플로이먼트가 잘 실행 중인 것을 볼 수 있다.
이제 위의 코드에서 레플리카셋의 수를 5로 아래와 같이 수정을 한다.

그 후 다시 실행을 하게 되면 앞에서 실행하고 있던 세 개의 파드 외에도 두 개의 파드가 추가되어 총 5개의 파드가 작동하는 것을 볼 수 있다.

롤아웃
롤아웃은 컨테이너 업데이트를 뜻하는 것으로 이미 배포되어있는 컨테이너를 수정할 수 있다.
아래의 과정은 배포된 컨테이너의 버전을 수정하는 내용이다.

생성된 파일을 통해 디플로이먼트를 실행하면 아래와 같이 Nginx버전이 1.24인것을 확인할 수 있다.

이제 위에서 만든 코드에서 Nginx의 버전만 1.25로 수정을 한다.

수정을 한 다음 현재 실행중인 파드의 Nginx버전을 아래와 같이 확인하면 수정한 결과인 1.25로 바뀐것을 볼 수 있다.

롤백
이때 만약 잘못 적용된 부분이 있어서 롤아웃 이전의 컨테이너 상태로 돌아가고 싶으면 아래와 같이 undo를 통해서 이전의 상태로 돌아가면 된다.
# 롤백
kubectl rollout undo deployment deploy-test01
그렇게 하면 아래와 같이 수정하기 전 버전인 Nginx 1.24인것을 볼 수 있다.

서비스
쿠버네티스 서비스는 클라이언트와 파드의 연결을 담당한다.
파드의 경우 일시적이기 때문에 언젠가 정지된다. 파드가 클라이언트에게 서비스를 제공하려면 클라이언트는 파드의IP에 요청을 하고 이때 각 파드는 개별적인 IP주소를 가진다.
만약 서비스중인 파드가 죽고 해당 서비스를 제공하는 새로운 파드 생기면 요청을 보낼 IP주소가 변경된다.
이때 쿠버네티스 서비스를 활용하면
파드에게 고유한 IP 주소와 파드 집합에 대한 단일 DNS 명을 부여하고, 그것들 간에 로드-밸런스 및 파드들에 대한 서비스 디스커버리를 가능하게 한다.
이때 서비스 디스커버리란 서비스를 구성하는 개별 인스턴스를 찾는 프로세스를 의미한다.
서비스를 사용하면 파드 내부를 수정하지 않아도 외부로 노출시킬 수 있는 장점이 있다.
ClusterIP
쿠버네티스 서비스의 기본 설정값으로 클러스터 내에서만 파드에 접근될 수 있도록 하는 유형이다.
클러스터 내부에서만 접근 가능한 IP를 할당하여 외부에서는 접근할 수 없다
# service-test01.yml파일
apiVersion: v1
kind: Service # 오브젝트 종류는 서비스
metadata:
name: web-service
spec: # 서비스 상태
selector:
app.kubernetes.io/name: web-deploy # 서비스에 연결할 파드
type: ClusterIP
ports:
- protocol: TCP
port: 80
서비스 파일을 작성할 때 해당 서비스와 연동될 디플로이먼드를 지정해줘야한다.
위에서는 web-deploy로 지정했다.

# nginx-test01.yml파일을 통해 생성하는 파드에서 서비스 요청 보냄
apiVersion: v1
kind: Pod
metadata:
name: nginx01
spec:
containers:
- name: nginx-test01
image: nginx:latest
앞서 생성한 쿠버네티스 서비스가 파드로부터 요청을 받아 정보를 제공한다.
이를 위해 요청할 파드를 생성하면 다음과 같이 할 수 있다.

그 후 Nginx파드를 다음과 같이 생성할 수 있다

exec명령어에 -it옵션을 통해 Nginx파드에 접속해 셀을 실행한다.
Nginx파드 내부에서 curl명령어를 활용해 서비스에 요청을 보내면 서비스의 IP주소와 포트 번호를 통해 접속이 잘 되는것을 볼 수 있다.

NodePort
NodePort는 각 노드의 특정 포트를 통해 외부 접근을 제공하는 유형이다.
NAT을 사용하는 클러스터 내에서 각 노드들의 지정된 포트를 외부에 노출시킨다.
[NodeIP]:[NodePort]를 이용해 클러스터 외부에서 서비스에 접근할 수 있게 해준다.
apiVersion: v1
kind: Service
metadata:
name: web-service-nodeport # 서비스 이름
spec:
selector:
app.kubernetes.io/name: web-deploy # 디플로이먼트 파일인 deploy-test01에서 생성한 web-deploy와 연동
type: NodePort
ports:
- protocol: TCP
nodePort: 31001 # 노드로 연결할 NodePort
port: 80 # 서비스가 사용하는 Port
targetPort: 80 # 파드가 받게 될 포트


NodePort접속을 위해 포트포워딩을 다음과 같이 설정하여 31051호스트 포트로 접속하면 10.0.2.16노드의 NodePort 31001로 포트포워딩하고 31061로 접속하면 10.0.2.17노드의 NodePort로 포트포워딩하게 한다.


포트포워딩을 하면 위와같이 접속이 잘 되는것을 볼 수 있다.

LoadBalancer
LoadBalancer는 서비스에 고정된 공인 IP를 할당한다.
이를 통해 IP및 포트 번호를 활용해 클러스터 외부에서 서비스에 접근할 수 있게 한다.
apiVersion: v1
kind: Service
metadata:
name: web-service-loadbalancer # 서비스 이름
spec:
selector:
app.kubernetes.io/name: web-deploy
type: LoadBalancer
ports:
- protocol: TCP
nodePort: 31002 # 각 노드로 접근할 포트
port: 80 # 서비스가 사용할 포트
targetPort: 80 # 파드가 사용할 포트
externalIPs: # 외부에서 접근할 수 있는 IP
- 10.0.2.15 # myserver01의 IP
로컬에서 웹 브라우저로 127.0.0.1에 80port로 접속을 하면 아래와 같이 잘 나오는 것을 볼 수 있다.

ExternalName
CNAME레코드를 통해 클러스터 외부 서비스로 DNS 조회를 제공하는 유형이다.
즉, 서비스가 클러스터 외부에 있는 도메인을 가리키도록 설정할 수 있다.
아래와 같이 서비스 yml을 작성한다.
apiVersion: v1
kind: Service
metadata:
name: web-service-externalname
spec:
type: ExternalName
externalName: www.google.com # 파드에서 연결할 외부 애플리케이션
그 후 apply를 통해 파일을 실행하면 파드와 서비스를 확인할 수 있다.

이제 파드 내부에서 web-service-externalname을 통해 구글에 접속한다.
실행하면 아래와 같이 뜨는데 404는 구글 사이트가 쿠버네티스 외부에 존재하는 리소스이기 때문에 그렇다.

이를 이미지로 나타내면 다음과 같다

스토리지 볼륨
컨테이너가 삭제될 때 파일을 보존하기 위해서 볼륨이라는 개념을 사용했는데 쿠버네티스에서는 컨테이너 파일을 보존하기 위해서 스토리지 볼륨을 사용한다.
컨테이너 내부 파일 시스템은 일시적인 스토리지를 제공하기 때문에 파드가 삭제된 후 다시 실행하면 기존의 파일이 다 사라진다.
따라서 이를 해결하기 위해 스토리지를 통해 노드 내부의 일부 디스크 공간을 파드와 공유하거나, 노드 외부의 스포리지 시스템과 연결하는 방식으로 데이터를 보존한다.
emptyDir
파드 내부에서 임시적으로 사용하는 볼륨으로 파드가 노드에 할당될 때 처음으로 생기고 실행되는 동안만 존재한다.
apiVersion: v1
kind: Pod
metadata:
name: nginx-volume-01
spec:
containers:
- name: nginx-test01
image: nginx:latest
volumeMounts:
- name: empty-test01 # 컨테이너가 사용할 볼륨 이름으로 이후 생성할 볼륨 이름과 일치해야한다.
mountPath: /mount01
volumes:
- name: empty-test01
emptyDir: {} # 추가 옵션 선택하지 않음

내부 파일 목록에 test.txt가 저장된것을 볼 수 있다.

생성한 파드를 삭제하고 다시 파드를 생성하면 이전에 생성한 test.txt파일이 없는것을 확인할 수 있다.
hostPath
호스트 노드의 파일 시스템으로부터 파일을 마운트하는것이다.
내부 경로에 볼륨을 두어 서로 다른파드이더라도 실행되는 노드가 동일하면 데이터가 유지된다.
이는 서로 다른 파드가 동일하게 데이터를 보관할 수 있는 장점이 있지만 노드 자체에 문제가 생긴다면 데이터가 유실될 수 있는 단점이 있다.

각각 hostname이 myserver01, 02, 03인 것을 볼 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx-volume-02
spec:
nodeSelector:
kubernetes.io/hostname: myserver03 # myserver03에 파드를 생성
containers:
- name: nginx-test01
image: nginx:latest
volumeMounts:
- name: hostpath-test01
mountPath: /mount01
volumes:
- name: hostpath-test01
hostPath:
path: /home/eevee/work/volhost01 # myserver03에서 hostPath볼륨을 생성할 경로
type: DirectoryOrCreate # 디렉터리가 존재하지 않는 경우 자동으로 생성
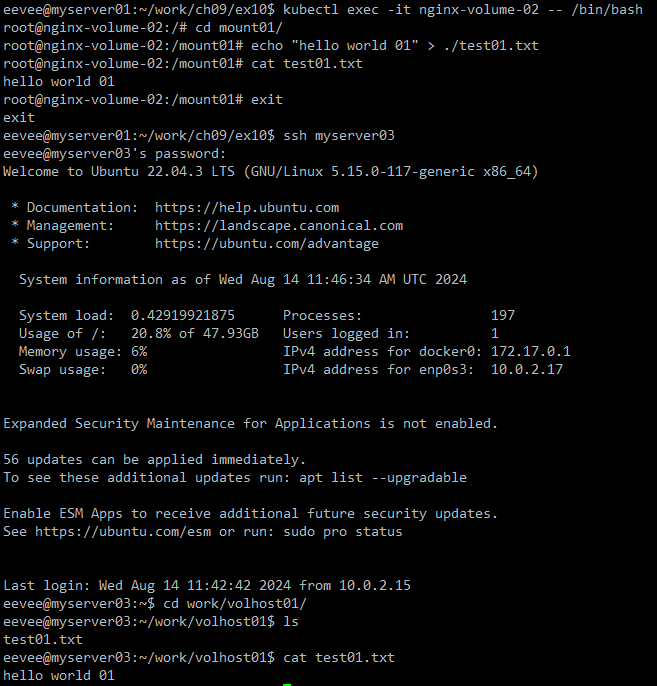
실행을 하고 ssh를 통해서 myserver03으로 이동해서 확인을 해보면 해당 노드에도 hostPath볼륨이 저장되어있는 것을 볼 수 있다.

파드를 삭제한 후 재생성해도 데이터가 유지되는 것을 볼 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx-volume-03
spec:
nodeSelector:
kubernetes.io/hostname: myserver02 # myserver02에 파드 생성
containers:
- name: nginx-test01
image: nginx:latest
volumeMounts:
- name: hostpath-test01
mountPath: /mount01
volumes:
- name: hostpath-test01
hostPath:
path: /home/eevee/work/volhost01
type: DirectoryOrCreate

실행 결과를 보면 nginx-volume-02파드는 myserver03 노드에서 실행이 되고, nginx-volume-03파드는 myserver02에서 실행이 된다.
다만 새로 생긴 파드의 경우 앞에서 생성한 test01.txt파일이 존재하지 않는 것을 볼 수 있다.
PV
pv는 persistent Volume의 약자로 외부 스토리지를 의미한다.
pv는 스토리지 자원을 의미하고 여기에 pvc는 스토리지를 동적으로 바인딩하기 위한 요청 객체를 말한다.
pv를 사용하기 위해서 nfs서버를 써야하는데 이는 원격 서버에 존재하는 파일들을 내 컴퓨터에 있는 것처럼 사용할 수 있게 해준다.
따라서 클라이언트에는 nfs-common을 설치하고, 서버 역할을 하는 노드에는 nfs-kernel-server도 추가로 설치해준다.
# NFS서버 설치
sudo apt install nfs-common
sudo apt install nfs-kernel-server


nfs서버가 공유하는 디렉터리를 설정한다.

nfs서버는 디렉터리를 myserver02인 10.0.2.16에게 허용을 한다.
rw는 읽기, 쓰기 권한을 주는것이고, no_root_squash는 루트 권한으로 쓰기 권한을 주는것이다.

# myserver03에 pv생성
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-01
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 100Mi # 용량 설정
persistentVolumeReclaimPolicy: Retain # PVC삭제되도 PV내부 데이터는 그대로 유지
storageClassName: pv-test-01
nfs:
server: 10.0.2.17 # NFS 서버 IP주소
path: /tmp/k8s-pv # NFS 서버 내부에서 PV로 사용될 경로
# PV와 연동할 PVC 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-01
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 30Mi
storageClassName: pv-test-01
# PersistentVolume실습
apiVersion: v1
kind: Pod
metadata:
name: nginx-volume-04
spec:
nodeSelector:
kubernetes.io/hostname: myserver02
containers:
- name: nginx-test01
image: nginx:latest
volumeMounts:
- name: nfs-pv-01
mountPath: /mount01
volumes:
- name: nfs-pv-01
persistentVolumeClaim:
claimName: pvc-01


nfs서버로 이동해도 앞의 파드 내부에서 생성한 파일이 존재하는 것을 볼 수 있다.

파드, pv, pvc를 모두 삭제해도 nfs서버에 데이터가 보관되고 있는 것을 볼 수 있다.
스테이트풀셋
구성되는 파드들이 서로 동일한 스팩이라고 하더라도 독자성을 유지하므로 대체해서 사용할 수 없다.
또한 각 파드는 영구적인 식별자를 가지는데 이는 스케줄링을 다시 할 때도 유지된다.
따라서 안정적이고 고유한 네트워크 식별자, 순차적인 원활한 배포와 스케일링 등과 같은 상황에서 유용하다.
# 헤드리스 서비스 생성
apiVersion: v1
kind: Service
metadata:
name: sfs-service01
spec:
selector:
app.kubernetes.io/name: web-sfs01
type: ClusterIP
clusterIP: None
ports:
- protocol: TCP
port: 80

헤드리스 서비스는 일반 서비스와 달리 클러스터 내에서 서비스 디스커버리(탐색) 기능만을 제공한다.
헤드리스 서비스는 일반적인 ClusterIP 서비스와 달리, 서비스에 고정된 IP 주소가 없으며, 클러스터 내에서 각 Pod의 IP 주소가 직접 노출된다.
EXTERNAL-IP 필드가 <none>으로 표시되는 것은 이 서비스가 헤드리스로 설정되었음을 알 수 있다.
# 스테이트풀셋 생성
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sfs-test01
spec:
replicas: 3
selector: # 파드를 하나로 묶어준다
matchLabels:
app.kubernetes.io/name: web-sfs01
serviceName: sfs-service01
template:
metadata:
labels:
app.kubernetes.io/name: web-sfs01
spec:
containers:
- name: nginx
image: nginx:latest

서비스를 보면 앞서 생성한 헤드리스 서비스가 실행중임을 볼 수 있다.
# 파드 개수 줄이기
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sfs-test01
spec:
replicas: 2 # 2개로 감소
selector:
matchLabels:
app.kubernetes.io/name: web-sfs01
serviceName: sfs-service01
template:
metadata:
labels:
app.kubernetes.io/name: web-sfs01
spec:
containers:
- name: nginx
image: nginx:latest

기존 파드가 세 개의 실행중이다가 파드가 2개로 줄어든 것을 볼 수 있다.
이때 가장 최근에 실행되었던 파드가 삭제된다.
# Nginx 파드 생성
apiVersion: v1
kind: Pod
metadata:
name: nginx01
spec:
containers:
- name: nginx-test01
image: nginx:latest

Nginx파드 접속 후 웹 서비스를 이용하려면 파드의 IP주소를 확인하고 아래와 같이 진행하면 된다.
위에서 sfs-test01-0의 IP주소를 확인하여 다음과 같이 해당 IP로 접속을 진행하면 다음과 같이 된다.

# 스테이트풀셋에 사용할 볼륨 생성
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-sfs01
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 100Mi
persistentVolumeReclaimPolicy: Retain
storageClassName: pv-sfs-test01
hostPath:
path: /home/eevee/work/volhost01
type: DirectoryOrCreate
# 스테이트풀셋 생성하는 yml파일
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sfs-test01
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: web-sfs01
serviceName: sfs-service01
template:
metadata:
labels:
app.kubernetes.io/name: web-sfs01
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts: 컨테이너 내부에 마운트할 볼륨 정보 입력
- name: sfs-vol01
mountPath: /mount01
volumeClaimTemplates:
- metadata:
name: sfs-vol01
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: pv-sfs-test01
resources:
requests:
storage: 20Mi

파드가 잘 생성되었고 스테이트풀셋이 실행중인 것을 볼 수 있다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sfs-test01
spec:
replicas: 2 # 파드의 수 증가
selector:
matchLabels:
app.kubernetes.io/name: web-sfs01
serviceName: sfs-service01
template:
metadata:
labels:
app.kubernetes.io/name: web-sfs01
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- name: sfs-vol01
mountPath: /mount01
volumeClaimTemplates:
- metadata:
name: sfs-vol01
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: pv-sfs-test01
resources:
requests:
storage: 20Mi
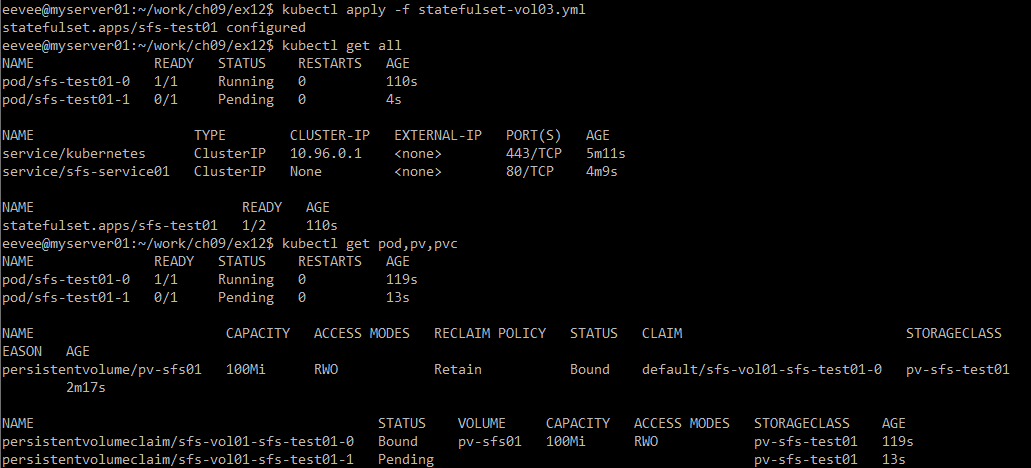
파드의 개수가 바뀌면 생성된 파드의 status가 pending으로 정상적으로 생성되지 않은 것을 볼 수 있다.

pending이 생긴 이유는 앞서 생성했던 sfs-test01-0이 이미 pv-sfs-test01인 볼륨을 사용하고 있기 때문에 이후에 만들어진 sfs-test01-1파드가 사용할 볼륨을 찾을 수 없어서 생긴 문제이다.
인그레스
인그레스는 쿠버네티스 클러스터 외부에서 내부에 존재하는 쿠버네티스 서비스에 접근하기 위해 HTTP/HTTPS를 활용한 라우팅 규칙을 제공하는 오브젝트이다.
인그레스를 통해 내부의 여러 서비스를 다수의 LoadBalancer없이도 외부에 노출 시킬 수 있으므로 프로덕션 환경에서 유용하게 사용할 수 있다.
하나의 인그레스에 여러 서비스가 포함될 수 있는데 URL접속시 경로 차이를 통해 다른 서비스에 연결할 수 있다.
인그레스를 사용하기 위해 헬름이라는 애플리케이션을 사용한다.
쿠버네티스에서는 하나의 애플리캐이션을 실행하기 위해서 파드, 서비스 등의 여러 리소스를 사용해야하는데 이를 위해서 여러 yaml파일의 관리가 필요하다.
따라서 헬름을 통해서 이러한 파일들을 하나의 패키지 형태로 관리하여 yaml파일을 생성하지 않고 쿠버네티스 환경에서 애플리케이션을 설치할 수 있다.
헬름 차트는 리소스를 생성하기 위해 필요한 파일을 모아놓은 디렉터로 설치에 필요한 여러 변수를 한 번에 설정하고 최적화 하기도 쉽다.
즉, 헬름 차트를 다운로드하여 해당 디렉토리에 있는 파일을 수정해 자신의 환경에 맞게 최적화 하여 쿠버네티스 클러스터에 설치한다.
헬름 설치는 아래의 사이트를 참고하여 진행하면 된다.
https://helm.sh/docs/intro/install/
Installing Helm
Learn how to install and get running with Helm.
helm.sh
그럼 아래의 이미지처럼 설치를 진행한다.

# 아래 경로를 bitnami라는 이름의 레포지토리로 추가
helm repo add bitnami https://charts.bitnami.com/bitnami

이제 트래픽을 관리할 수 있는 nginx ingress controller를 설치할 것이다.

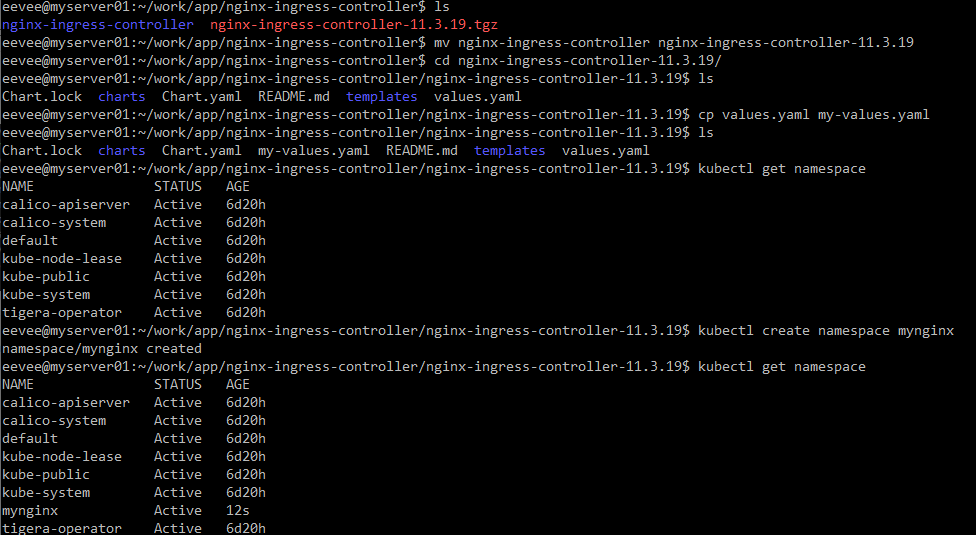
이처럼 해당 파일을 다운로드하고 압축을 푼 뒤 파일 이름을 바꾸는 과정을 진행하였다.
그 후 nginx-ingress-contoller를 설치할 namespace를 생성해준다.

--namespace를 통해 설치될 네임스페이스를 정하고 --generate-name을 통해 랜덤하게 이름을 생성시킨다.

mynginx네임스페이스에서 실행중인 오브젝트를 확인하여 원활하게 작동중임을 확인할 수 있다.
추가로 외부에서 접근할 수 있는 EXTERNAL-IP가 pending으로 되어있는데 이는 IP를 할당받지 못했기 때문에 생긴것으로 이후에 IP를 할당해주면 된다.
이제 온프레스미 상황에서 자체 LoadBalancer를 생성해 자동으로 IP를 부여할 수 있도록 하겠다.

먼저 kube-proxy의 strictARP를 true로 바꿔줘야한다.
왜냐하면 온프레미스 환경에서 자체 LoadBalancer를 생성할 때 ARP 문제를 방지하고, 정확한 서비스 트래픽 라우팅을 보장하기 위해서이다.
이 과정을 통해서 클러스터 내의 서비스 IP가 올바르게 ARP(주소 해석 프로토콜)를 통해 네트워크에서 감지되고 사용될 수 있도록 조정한다.
그 후 metallb를 다운로드한다.
MetalLB는 Kubernetes 클러스터에서 온프레미스(자체 데이터 센터 또는 로컬 서버 환경) 환경에서 LoadBalancer 타입의 서비스를 사용할 수 있게 해주는 네트워크 부하 분산 소프트웨어이다.
일반적으로 Kubernetes의 LoadBalancer 타입 서비스는 클라우드 환경에서 클라우드 제공업체의 네트워크 로드 밸런서를 사용하여 외부 트래픽을 클러스터 내부의 서비스로 라우팅한다.
그러나 온프레미스 환경에서는 이러한 기능이 기본적으로 제공되지 않기 때문에 MetalLB와 같은 솔루션이 필요하다.

metallb를 설치할 네임스페이스를 생성한다.

speaker와 controller가 정상적으로 running인것을 볼 수 있다.
그리고 metallb-webhook-service는 클러스터 내부에서만 사용하기 때문에 EXTERNAL -IP가 none인것을 볼 수 있다.
---
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: my-metallb-config
namespace: mymetallb
spec:
addresses:
- 10.0.2.20-10.0.2.40 # metallb가 사용할 IP주소 범위를 설정한다.
autoAssign: true
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: my-metallb-config
namespace: mymetallb
spec:
ipAddressPools:
- my-metallb-config
IP범위를 정할때는 쿠버네티스 클러스터 IP범위를 포함하지 않는 영역으로 해야한다.
왜냐하면 Kubernetes 클러스터 내부에는 서비스 클러스터 IP, 노드 IP, Pod IP 등의 IP 범위가 이미 할당되어 있다.
이 IP 범위와 MetalLB가 관리하는 외부 LoadBalancer IP 범위가 겹치면, 두 개의 다른 네트워크 엔티티가 동일한 IP를 사용할 수 있는 상황이 발생한다.
경우, 트래픽이 어느 쪽으로 가야 할지 네트워크가 혼란스러워하고, 결과적으로 네트워크 통신이 불안정해지거나 실패할 수 있다.

my-config.yaml파일을 실행하여 결과를 보면 my-metallb-config가 잘 실행되는 것을 볼 수 있다.
그리고 describe를 통해서 더 자세한 정보를 살펴보면 IP주소 범위가 우리가 설정한 범위로 잘 실행되는 것을 볼 수 있다.

아래의 Events에서 metallb로부터 nginx-ingress-controller가 IP주소를 할당 받았다는 내용을 확인할 수 있다.

# 인그레스에 연동할 디플로이먼트 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-deploy-test01
spec:
replicas: 3
selector:
matchLabels:
app.kubernetes.io/name: web-deploy01 # selector로 적용하는 이름으로 파드를 생성할 때의 이름과 동일
template:
metadata:
labels:
app.kubernetes.io/name: web-deploy01
spec:
containers:
- name: nginx
image: nginx:1.25
# 서비스를 생성
apiVersion: v1
kind: Service
metadata:
name: ingress-service-test01
spec:
selector:
app.kubernetes.io/name: web-deploy01 # 앞서 만든 디플로이먼트 파일의 web-deploy01과 연동
type: ClusterIP
ports:
- protocol: TCP
port: 80
targetPort: 80
# 인그레스를 생성
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-test01
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / # 이후 URL접근 경로를 루트 경로로 변경
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /test01
pathType: Prefix # 경로의 접두사가 일치하는 경우 적용
backend:
service:
name: ingress-service-test01
port:
number: 80

쿠버네티스 클러스터 외부에서 인그레스로 요청을 보내면서 서비스 이용이 가능하다.

# 두 번째 웹 서비스 배포를 위한 디플로이먼트 파일
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-deploy-test02
spec:
replicas: 3
selector:
matchLabels:
app.kubernetes.io/name: web-deploy02
template:
metadata:
labels:
app.kubernetes.io/name: web-deploy02
spec:
containers:
- name: nginx
image: nginx:1.25
# 인그레스 파일 생성
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-test02
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /test01
pathType: Prefix
backend:
service:
name: ingress-service-test01
port:
number: 80
- path: /test02
pathType: Prefix
backend:
service:
name: ingress-service-test02
port:
number: 80
# 서비스 생성위한 파일
apiVersion: v1
kind: Service
metadata:
name: ingress-service-test02
spec:
selector:
app.kubernetes.io/name: web-deploy02
type: ClusterIP
ports:
- protocol: TCP
port: 80
targetPort: 80
먼저 test01 디플로이먼트와 서비스를 실행을 하고 test02에 대해서도 실행을 하면 아래와 같은 결과롤 볼 수 있다.
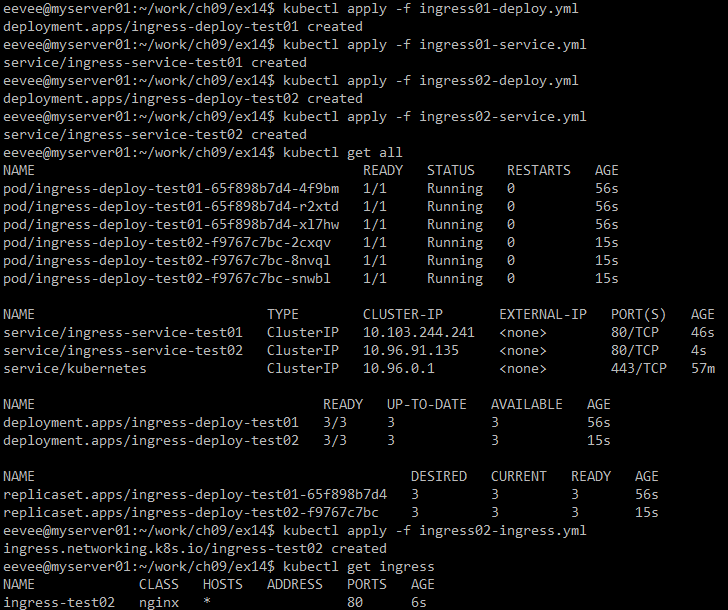


실행 결과를 보면 위처럼 웹 브라우저를 통해서 접속이 잘 되는것을 볼 수 있었다.
잡과 크론잡
잡은 쿠버네티스 애플리케이션의 실행 및 종료에 초점을 맞춘것으로 잡을 통해 파드를 생성하고 종료될 때 까지 계속 파드의 실행을 재시도한다.
그리고 지정된 수의 성공완료 회수에 도달할때 까지 계속된다.
크론잡의 경우 반복되는 일정에 따라 잡을 만드는데 특정 주기마다 반복해서 실행을 한다.
apiVersion: batch/v1
kind: Job
metadata:
name: job-test01
spec:
template:
spec:
containers:
- name: nginx-test01
image: nginx:1.25
command: ["echo", "Hello, Kubernetes!"] # Job을 통해 입력할 명령어 추가
restartPolicy: Never
backoffLimit: 3

descrive를 통해 job-test01을 보면 잡 컨트롤러에 의해 잡이 완료되었다는 것을 볼 수 있다.
크론잡 사용
# 크론잡
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-test02
spec:
schedule: "*/1 * * * *" # 스케줄 설정으로 1분에 1번씩 실행 한다
jobTemplate:
spec:
template:
spec:
containers:
- name: nginx-test02
image: nginx:1.25
command:
- /bin/sh
- -c
- echo Hello Kubernetes!
restartPolicy: Never

생성한 크론잡 정보를 위처럼 볼 수 있고 우리가 설정한 시간이 지나면 이미지의 아래처럼 이벤트가 생성된것을 볼 수 있다.
이제 log를 통해서 처리된 내용을 확인하면 다음과 같다.

'컴퓨터 > 도커' 카테고리의 다른 글
| 7. 쿠버네티스 클러스터 관리 및 소스코드 관리 (1) | 2024.09.01 |
|---|---|
| 6. 쿠버네티스를 활용한 웹 서비스 배포 (0) | 2024.08.23 |
| 4. 쿠버네티스설치 및 기본 개념 (0) | 2024.08.08 |
| 3. 도커 실습 (1) | 2024.08.03 |
| 2. 도커 기초 (0) | 2024.07.28 |



