코드를 실행하게 되면 많은 시간이 loop구문에서 소비되게 된다.
따라서 반복되는 부분을 최적화 한다면 빠른 속도를 얻을 수 있다.
Dominator
모든 CFG는 start node s0가 있고 이는 predecessor가 없다
그리고 d dominates n이라는 것은 만약 s0에서 n으로 직선 경로가 주어질 때 무조건 d를 지나야 n에 도달할 수 있을 때를 의미한다.
Dom[n]은 노드 n에 dominate되는 모든 노드 집합을 의미한다.
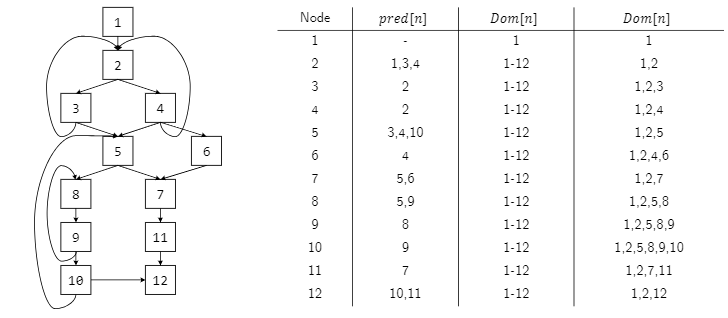
Immediate Dominator
노드n 바로 직전의 마지막 dominator를 의미한다.
IDom[n]으로 표기하고 이는 자기 자신이 될 수 없고, n을 dominate한다.
그리고 n의 다른 dominator를 dominate하지 않는다.
따라서 모든 노드 n은 정확히 하나의 immediate dominator를 가진다.

Post Dominator
모든 CFG가 하나의 exit노드 x를 가지고 이 노드에서 successor는 없다.
p post-dominate n라는 것은 n으로부터 시작해서 x로 가는 모든 경로에서 p노드를 거쳐가야한다.
post-dominate분석은 dominate분석과 유사한데 단지 진행되는 방향이 반대이기 때문에 이를 반대로 생각하면 된다.
post-dominate분석은 만약 n이라는 노드가 m이라는 노드의 post-dominator라고 한다면 중간에 다른 노드가 있더라고 영향을 받지 않고 n에 의해서 영향을 받는다는 뜻이므로 control dependence를 계산하는데 유용하다.
Loop
CFG노드의 집합S에서 header node가 존재해 S의 다른 노드를 다 dominate해야한다. 즉, S에 있는 노드들이 항상 h라는 header node를 거쳐서 실행되야한다.
이때 header로 시작해 다른 노드로 가는 경우가 항상 존재해야하고, h가 predecessor가 s에 있지 않은 유일한 노드여야 한다.
그리고 S의 어떤 노드에서도 h로 돌아갈 수 있는 경로가 있어야 한다.
loop은 single entry를 가지고 여러개의 exit영역을 가질 수 있다.


Loop가 안되는 경우를 보면 왼쪽 부분은 밖에서 들어오는 에지가 1번에만 있으므로 1번이 header가 되야하는데 처음의 경우 2번과 3번에서 1번을 갈 수 있는 edge가 없다.
오른쪽의 경우는 봐도 1번으로 돌아올 수 있는 경우가 없고 만약 header를 다른것으로 본다면 entry가 여러개여서 안된다.
Natural Loop
header노드 h가 n을 dominate하는데 n에서 h로 가는 edge가 있을 때 이 edge를 back edge라고 한다.
natural loop of back edge<n, h>라고 한다면 loop header h가 있을 때 노드의 집합X에서 각각의노드가 h에 의해서 dominate당하고 x에서 n으로 가는 h를 거치지 않고 가는 경우가 있어야 한다.

loop preheader
loop preheader는 반복문에서 변수를 초기화 하는등 loop header바로 직전에 코드를 삽입해야하는 경우 필요하다.
for(int i = 0; i < n; i++){
}이처럼 for문에서 i = 0으로 초기화 해주는 부분이다.
Loop optimization
루프에서 많이 반복되는 부분은 inner loop이기 때문에 이 부분을 먼저 최적화를 한다.
loop invariant code mation
loop안에 statement가 있을 때 루프를 돌때 매변 값이 바뀌지 않고 동일하게 있는 변수a1, a2가 있을 때 이를 찾으면 statement s를 hoist(loop내부에서 밖으로 끌고 나옴)해서 한 번만 실행하고 실행시간을 절약한다.
다만 변수가 매번 같은 값인지 확인하기 힘들기 때문에 컴파일러는 보수적이고 증명적인 것을 사용해야하기 때문에 사용하기 어렵다.
따라서 ai변수가 constant이거나 모든 정의가 loop밖에 있는것이 확인되면 사용할 수 있다.
induction variable analysis
induction variable은 루프 l안의 변수i가 loop와 상관없는 값에 의해서 증가하거나 감소하는 것을 의미한다.
즉, 상수의 값에 의해서 i++와 같이 증가하거나 감소하는 경우를 뜻한다.
basic inductino variable: 상수에 의해서 증가하거나 감소하는 경우
derived inductino variable: 다른 induction variale에 의해서 선형적으로 정의되는 경우로 j = k * c 또는 j = k + d형태로 정의가 되야한다. 이때 k가 induction variable이라면 c, d는 loop invariant이고, k가 derived inducion인 경우 k의 정의가 1개여야 하고 k = i * c라고 할때 k와 j사이에 i가 새로 정의되서는 안된다.
strength reduction
일반적으로 사용되는 최적화 기법이지만 최적화가 아닌 다른 곳에도 쓰일 수 있다.
이는 비싼 연산을 싼 연산으로 바꿔서 최적화를 한다.
만약 i = i + c라고 할때 j = a + b * i 라고 하면 j 는 b * c만큼 증가한다.
이는 constant이기 때문에 미리 계산을 해서 쓸 수 있다.
induction variable elimination
induction variable이 비교문에만 사용하는 경우 loop내에서는 필요가 없기 때문에 삭제를 해준다.
이는 루프 내부에서 사용이 되긴 하지만 자기 자신만 갱신하는 경우 유용한 동작을 하지 않기 때문에 삭제한다.
Loop fusion
두개의 loop를 합쳐서 비교, 변수 업데이트 하는 loop overhead를 줄이기 위해서 사용한다.
이때 루프가 같은 범위에 들어가 있어야 하고 nested loop이 깊이도 같아야 한다.
그리고 loop-carried true dependece가 없어야 하는데 loop iteration사이의 의존도 루프 전 후 과정에서의 의존성이 없어야 한다는 뜻이다.

Loop fission
합쳐져있는 loop를 쪼개는 것으로 loop overhead보다 메모리에 접근하는 locality를 높이기 위해서 사용한다.
예를들어 캐시 성능을 향상시키기 위해서 해당 영역에만 접근할 수 있게 코드를 나눠 근처의 영역에만 접근하게 코드를 만든다.
또한 multi threading을 할때 코드를 나눠서 서로 각자 실행되게 하기 위해서 사용한다.

Loop splitting
loop되는 구간을 쪼개서 분리한다.
예를들어 실행되는 함수가 숫자가 작을때는 비효율적이여서 특정 조건에만 실행되게하여 작은 숫자인 경우는 그냥 계산하고 숫자가 큰 경우만 다른 함수로 계산하는 방식을 사용한다.
Loop peeling
루프 초반에만 다른코드를 실행할 때 그 부분을 루프전에 다 실행하고 나머지 부분을 루프로 실행시키는것이다.

Loop unrolling
제일 많이 사용하는 최적화 방식으로 루프를 반복하게되면 처음에 비교하게 되는 연산을 하게 되는데 이 부분을 줄이기 위해 반복되는 내용을 한번에 비교로 여러개 실행하게 하여 iteration수를 줄인다.

Loop tiling
matrix multiplication을 할때 많이 사용하는 것으로 일부의 영역에만 접근하여 메모리 작은 메모리 영역에서 업데이트를 하고 점점 영역을 확장하는 방향으로 진행한다.
이는 캐시를 최대한 잘 활용하기 위해서 해당 사이즈 만큼 연산을 하여 속도를 높인다.

Loop setioning
1-dimensional tiling으로 cpu와 같이 벡터연산을 할때 벡터의 크기에 맞게 sectioning을 진행하여 벡터 연산으로 여러개의 연산을 한번에 계산을 하는걸 도와준다.

Loop interchange
우리가 다차원 데이터라고 생각하는 것도 실제 컴퓨터에서는 일렬로 저장되어 있는데 따라서 연속된 것에 먼저 접근하는 것이 효율적이기 때문에 nested loop에서 연산되는 순서를 바꿔서 locality를 높이는 역할을 한다.

optimizatino blocker
procedure call
아래의 예시를 보면 비교문에 string length함수가 사용되는데, 함수로 사용되기 때문에 결과값은 상수이지만 컴파일러가 함수라는 것에는 side effect가 생길 수 있어서 구체적으로 파악하기 힘들어 최적화를 하지 못한다.

이러한 경우 inline으로 함수를 실행하게 되면 함수를 실행하는게 아니라 함수 내용의 body부분을 붙여넣어 실행하기 때문에 최적화가 가능하다.
혹은 루프 밖에서 함수 선언을 해 계산을 끝낸 값을 사용하여 최적화를 한다.
memory aliasing
pointer가 가리키는 부분을 컴파일러가 파악하기 힘들어 최적화가 힘들다.
다음과 같은 부분에서 a와 b가 연관이 없다는 것을 파악하기 힘들어서 최적화 하기 힘들다.

'컴퓨터 > 컴파일러' 카테고리의 다른 글
| 10. Register Allocation (4) | 2024.07.23 |
|---|---|
| 9. Liveness Analysis (2) | 2024.07.22 |
| 8. Instruction Selection (1) | 2024.07.19 |
| 7. Basic Blocks and Traces (2) | 2024.07.19 |
| 6. Translation to Intermediate Code (1) | 2024.07.19 |



